Gracias a un nuevo análisis del genoma, un equipo de investigación del Broad Institute del Massachusetts Institute of Technology (MIT) y la Universidad de Harvard, del Massachusetts General Hospital (MGH) y la Harvard Medical School (EE.UU.) identificó en gran parte de la población el riesgo de desarrollar cinco de las patologías comunes más graves, como las cardiovasculares, el cáncer de mama o la diabetes tipo 2.
El nuevo estudio, publicado en Nature Genetics, permitió crear un marcador de riesgo poligénico, utilizando información de más de seis millones de lugares en el genoma.
Los resultados determinan el riesgo de sufrir estas enfermedades e indican también la probabilidad de que una persona desarrolle condiciones potencialmente fatales ante de las primeras señales de alarma.
“Sabemos desde hace mucho tiempo que hay personas que corren un alto riesgo de contraer enfermedades, basándose únicamente en su variación genética general”, explica el autor principal Sekar Kathiresan, director de la Iniciativa de Enfermedades Cardiovasculares en el Broad Institute y director del Centro de Medicina Genómica en el MGH.
“Ahora podemos medir ese riesgo, usando datos genómicos de una manera significativa. Desde una perspectiva de salud pública, necesitamos identificar estos segmentos de mayor riesgo de la población para proporcionar la atención adecuada”, aclara Kathiresan, también profesor de Medicina en la Harvard Medical School.
El trabajo se realizó con datos de 400 mil individuos del Biobank de Reino Unido, pero sugiere que, por ejemplo, unos 25 millones de personas en EE.UU. podrían tener hasta tres veces más riesgo de lo normal de sufrir una enfermedad cardiovascular, según la variación genética. Esta información genómica podría permitir a los médicos mejorar la atención personal de estos pacientes con intervenciones tempranas para prevenir la enfermedad.
El equipo combinó algoritmos para desarrollar este marcador de riesgo poligénico. Para ello, los científicos primero reunieron datos de estudios de asociación de genoma a gran escala para identificar variantes genéticas vinculadas con enfermedades cardiovasculares, la fibrilación auricular, la diabetes tipo 2, la enfermedad inflamatoria intestinal o el cáncer de mama.
Para cada patología, aplicaron un algoritmo computacional para combinar la información de todas las variantes –que tienen a escala individual un impacto muy pequeño sobre el riesgo– en un solo número o marcador de riesgo. Este número podría usarse para predecir las probabilidades de que una persona sufra estas enfermedades según su genoma.
Asimismo, las personas con altas puntuaciones en este marcador para las patologías del corazón no necesariamente exhiben otros signos de alarma, como la hipertensión o el colesterol alto.
“Estas personas, que multiplican el riesgo de tener un ataque al corazón por los efectos acumulativos de muchas variaciones, en su mayoría no son detectables”, subraya Amit V. Khera, coautor de la investigación y cardiólogo en el MGH. “Si vinieran a consulta, no sería capaz de distinguirlos como de alto riesgo con nuestras métricas estándar. Hay una necesidad real de identificar estos casos para que podamos centrarnos en su detección y en los tratamientos de manera más efectiva”, prosigue.
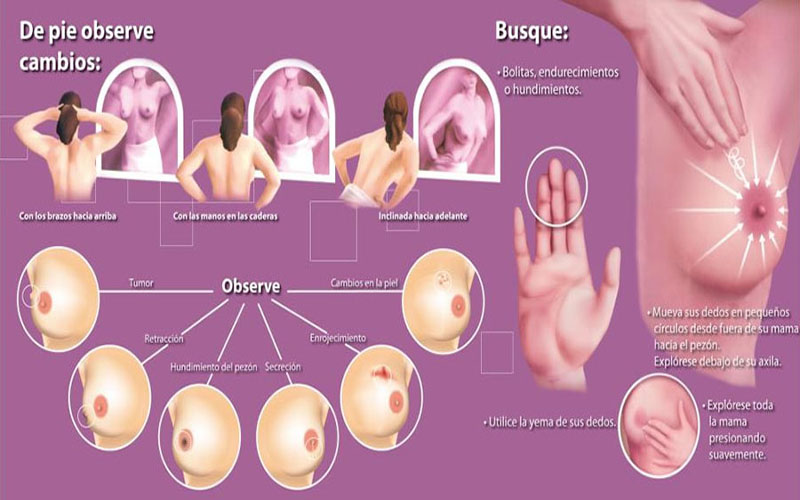
Los resultados revelan que el 8 por ciento de los datos de personas analizadas en el Biobank británico tenían más del triple de probabilidades de sufrir un ataque cardiaco en comparación con los demás. Para el cáncer de mama, el marcador encontró que el 1,5 por ciento de la población triplicaba el riesgo de tener la enfermedad.
A través de este marcador, los científicos podrían identificar a las personas con un riesgo alto o bajo de una enfermedad desde el nacimiento. “Luego usamos esa información para dirigir las intervenciones, ya sea modificando el estilo de vida o con tratamientos, para prevenir la patología. Para el ataque al corazón, cada paciente podría tener la oportunidad de conocer su número de riesgo poligénico en un futuro cercano, como quien conoce su nivel de colesterol ahora”, recalca Sekar Kathiresan.
El equipo de investigación subraya la necesidad también de ampliar los estudios a otros grupos étnicos para garantizar la equidad, ya que en este caso la información sobre la que se basa este trabajo es principalmente de individuos de ascendencia europea.